Private RAG Chatbot with Stained Glass Transform Proxy and Langchain¶
This notebook demonstrates how to build a private chatbot with a Retrieval Augmented Generation (RAG) architecture with a Stained Glass Transform Proxy, Langchain, Qdrant, and Gradio.
Overview¶
In today's data-driven world, leveraging large language models (LLMs) have become essential for developing intelligent applications. However, when dealing with sensitive information—-common in sectors like finance—-the challenge is to harness these powerful models without compromising data privacy. How can we build a chatbot that is both knowledgeable and respects the confidentiality of proprietary data?
This tutorial addresses that challenge by guiding you through the creation of a private chatbot using a Retrieval Augmented Generation (RAG) architecture enhanced with the Stained Glass Transform Proxy. We'll integrate key technologies such as LangChain, Qdrant, and Gradio to build a secure and user-friendly application.
Why Retrieval Augmented Generation (RAG)?¶
LLMs are impressive but their knowledge is inherently limited to the data they were trained on up to a certain cutoff date. This means they cannot know about private data they've never seen, nor can they be aware of recent events outside of its training data. RAG overcomes this limitation by retrieving relevant information from an external knowledge base to augment the LLM's responses. This approach ensures up-to-date and contextually relevant interactions.
The Privacy Challenge¶
Augmenting LLMs with external data often involves sending sensitive documents in plaintext to the model, raising significant privacy concerns. Traditional encryption methods fall short because the data must be decrypted before processing (otherwise it is unintelligible to the model), exposing it to potential risks.
The Solution: Stained Glass Transform¶
Stained Glass Transform is a model-native, privacy-preserving technique for transforming input to a machine learning model, so that its contents are obfuscated, but remain intelligible only to the target model, without any need for decoding. The Stained Glass Transform Proxy, a REST API compatible with OpenAI clients, uses Stained Glass Transform to transform inputs before sending to an LLM for inference. This standardized interface makes it easy to integrate Stained Glass Transform with existing applications and services that are already compatible with OpenAI's API.
What We'll Build¶
In this tutorial, you will learn how to:
- Create a secure chatbot application that respects data privacy.
- Use LangChain to construct a pipeline for uploading and retrieving documents from a Qdrant vector database.
- Integrate Gradio to develop an intuitive web interface, enabling users to upload documents, ask questions, and interact with the chatbot.
- Deploy the Stained Glass Transform Proxy to transform inputs securely before they reach the LLM, simply by adjusting the model provider's API connection details.
Tools and Technologies¶
-
LangChain: A framework that simplifies the development of applications combining LLMs with external data, tools, and APIs. It allows you to chain multiple operations to build dynamic workflows.
-
Gradio: An open-source Python library for creating user-friendly web interfaces. It streamlines the process of building interactive demos and sharing models through a browser-based platform.
-
Qdrant: An open-source vector search engine optimized for high-dimensional embeddings. It's ideal for semantic search, recommendation systems, and clustering large datasets.
-
Stained Glass Transform: A privacy-preserving technique that protects inputs for LLMs without the need for decoding. It ensures data privacy while maintaining model performance.
-
Stained Glass Transform Proxy: A privacy-preserving REST API that transforms inputs for LLMs without the need for decoding. It ensures data privacy while maintaining model performance. You can download the docker image from https://shorturl.at/i4224.
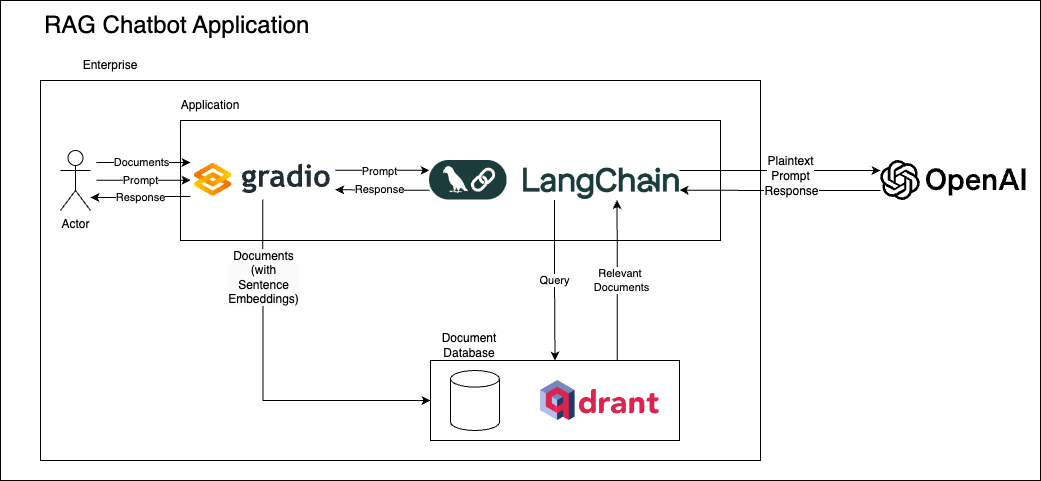
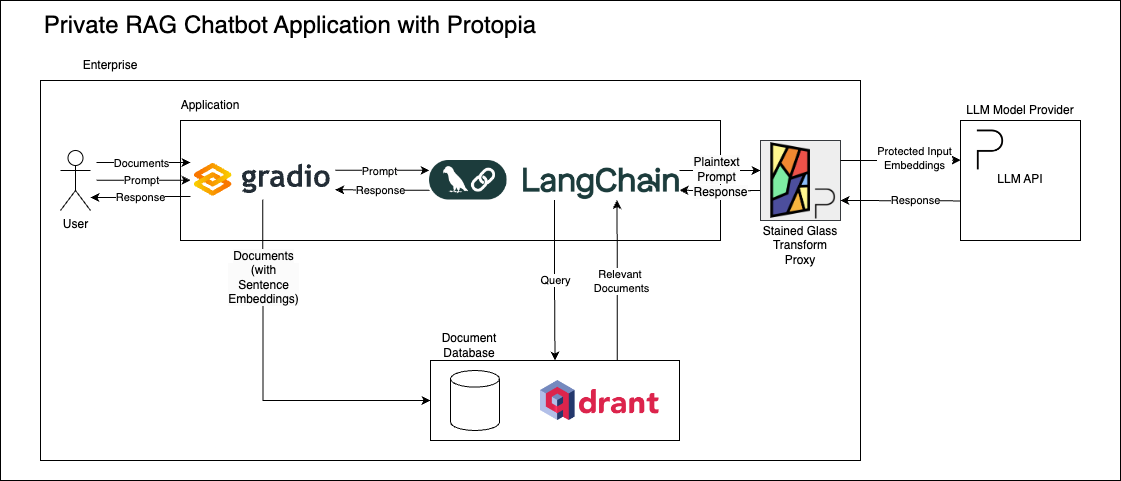
Architecture Diagrams¶
The following diagrams illustrate the architecture of the private chatbot with Stained Glass Transform Proxy, Gradio, LangChain, and Qdrant. The first diagram represents the workflow of the RAG chatbot application, using the official OpenAI API. The second diagram shows the enhanced architecture with the Stained Glass Transform Proxy, which ensures data privacy by transforming inputs before they reach the LLM. Note how that Gradio/LangChain application is unchanged between the two, and only the connection to the model provider's API is adjusted.
Install Dependencies¶
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["GRADIO_ANALYTICS_ENABLED"] = "false"
%pip install -q langchain==0.3.3 \
langchain-community==0.3.2 \
langchain-huggingface==0.1.0 \
langchain-openai==0.2.2 \
langchain-qdrant==0.1.4 \
pypdf==5.0.1 \
qdrant-client==1.12.0 \
openai==1.51.2 \
gradio==4.44.1 \
einops==0.8.0
Note: you may need to restart the kernel to use updated packages.
Deploy Qdrant Vector Database¶
In order to use RAG, your pipeline requires some sort of retrieval mechanism. Any text retrieval mechanism could be used, such as traditional database queries or algorithms for ranking documents, but vector-based retrieval (often called "vector search" or "similarity search") is a common approach in RAG pipelines. Qdrant, an open-source vector database, provides an simple and efficient way to implement a vector search engine for this tutorial. LangChain provides connectors for most common databases, so this tutorial can be adapted to use other databases as well.
Vector databases work by using "sentence embeddings" (sometimes called "document embeddings") for each item in their database. These embeddings, which are vectors of numbers, capture the meaning of the text in a way that if two documents are similar in meaning, their embeddings will be "close together" in the vector space. These sentence embeddings are created using a special kind of language model called a "Sentence Transformer". These are different than language models used for generating text, like GPT-4 or Llama3.
Once the sentence embeddings are created, they are added to a "vector database". This is a special kind of database that is optimized for quickly finding the closest embeddings to a given query embedding. This is useful for finding similar documents to a given query.
We will use Qdrant to store the embeddings of the documents. You can install Qdrant by following the instructions in the Qdrant documentation, or you can use the following Docker command below (you need to have Docker installed). Running the cell will start a Qdrant instance on your local machine.
import subprocess
QDRANT_PORT = 6333
QDRANT_HOST = f"http://localhost:{QDRANT_PORT}"
# Launch qdrant docker container
qdrant_container_id = subprocess.run(
f"docker run -d -p {QDRANT_PORT}:{QDRANT_PORT} -e QDRANT__TELEMETRY_DISABLED=True qdrant/qdrant",
shell=True,
encoding="utf-8",
capture_output=True,
).stdout.strip()
print(f"""Container {qdrant_container_id} started.
Run docker logs -f {qdrant_container_id} to see logs.""")
Container c3a3ec74342c29a4eb87292b30057b395dfb48808a0b84b26e04206199721ea9 started. Run docker logs -f c3a3ec74342c29a4eb87292b30057b395dfb48808a0b84b26e04206199721ea9 to see logs.
import pathlib
import langchain.chains
import langchain.chains.combine_documents
import langchain.docstore.document
import langchain.document_loaders
import langchain.prompts
import langchain.text_splitter
import langchain_community.chat_message_histories
import langchain_core.runnables.history
import langchain_huggingface
import langchain_openai
import langchain_qdrant
import qdrant_client
import qdrant_client.models
Adding Documents to Vector Database¶
As described above, RAG requires a retrieval mechnaism to find relevant documents to augment the LLM's responses. We are using Qdrant, so we need to create a LangChain chain to upload documents a user provides to the Qdrant vector database.
The process of preparing the vector database has several steps:
- Load the Sentence Transformer model.
- Create the Qdrant collection (if it doesn't already exist).
- Load and split documents into small chunks.
- Create sentence embeddings for each chunk. (These are different than the input/token embeddings we will see later on.)
- Add the embeddings to the Qdrant collection.
Tip
Generally, documents are only added to a vector database once. If you update the embedding model, however, you will have to recreate the embeddings and vector store, as embeddings between different models are not directly comparable.
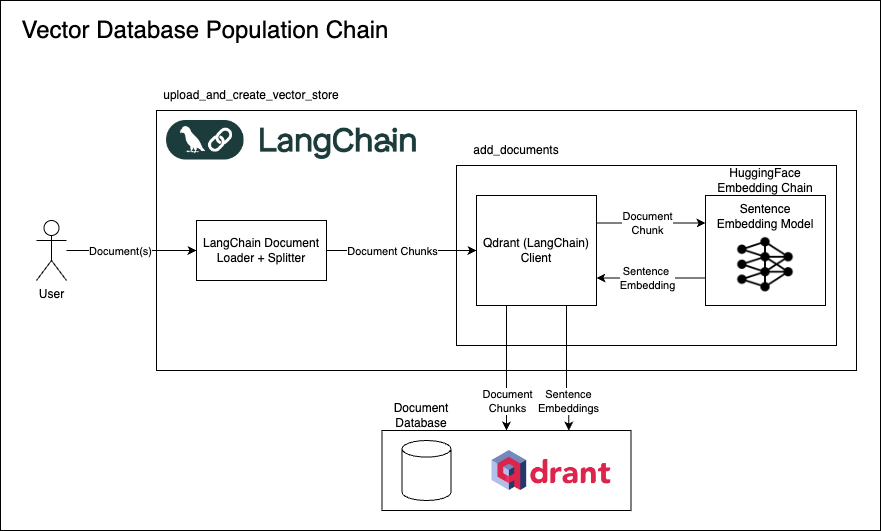
Architecture Overview¶
The diagram below illustrates the internal flow of the various LangChain components we will construct and use to upload documents to the Qdrant vector database.
Load the Sentence Transformer model¶
In order to use a vector database, we need a model that can create sentence embeddings. In this tutorial, we will use the jxm/cde-small-v1 Sentence Transformer from Alibaba to create sentence embeddings for our documents. LangChain will automatically download the model from the Hugging Face Hub if it is not already downloaded.
LangChain also provides convenient wrappers around Hugging Face Sentence Transformer models (langchain_huggingface.HuggingFaceEmbeddings) and Qdrant (langchain_qdrant.QdrantClient) to make it easy to create sentence embeddings and add them to a Qdrant collection.
We will use the Cosine Similarity to find the most similar documents to a given query. The exact specifics of how sentence embeddings and similarity search work are beyond the scope of this tutorial, but you can find more information online, such as Qdrant's vector search explainer.
Tip
The "best" embedding model depends on your specific use case, and new models are released all the time. jxm/cde-small-v1 is a good model for general-purpose sentence embeddings, and (at the time of writing) is high (relative to others of its size) on the Overall (English) category of the Massive Text Embedding Benchmark (MTEB) Leaderboard. You can find more information about the MTEB Leaderboard here. This model was chosen to be a good balance of performance and speed, but you may want to experiment with other models for your specific use case.
Note
The DOCUMENT_ENCODE_KWARGS and QUERY_ENCODE_KWARGS global constants here will depend on the specific Sentence Transformer model you are using. For many, if not most, models, the default None will work fine. Some models, however, use different schema for queries vs documents or have other special requirements. You can usually find more information in the model's documentation or on the Hugging Face Hub. LangChain supports passing in these special arguments as shown below.
The jxm/cde-small-v1 model is one model that does require special arguments, so we have included them here. The model expects documents to be prefixed with document: and queries to be prefixed with query:, and has suboptimal performance if these prefixes are not included. LangChain will automatically pass these arguments to the Sentence Transformer model when creating embeddings, handling the prefixes for you.
from typing import Any
EMBEDDING_MODEL_ID = "jxm/cde-small-v1"
MODEL_KWARGS: dict[str, Any] | None = {
"device": "cpu",
"trust_remote_code": True,
}
DOCUMENT_ENCODE_KWARGS: dict[str, Any] | None = {"prompt_name": "document"}
QUERY_ENCODE_KWARGS: dict[str, Any] | None = {"prompt_name": "query"}
Sentence Transformers, like many language models, usually have a limit on the input size (often called a "context length"). Consequently, this means that for long documents, we need to split them into smaller chunks that fit inside the context length.
The jxm/cde-small-v1 model has a context length of 512 tokens (approximately 2,048 characters, as tokens have variable length), but for computational efficiency, we will split the documents into smaller chunks.
Tip
Each sentence transformer has its own context length for which it was trained. You will get the best results if you use chunks that are close in size to the context length of the sentence transformer you are using (without going over). For example, if you are using a sentence transformer with a context length of 512 tokens, you should split your documents into chunks of approximately 512 tokens. The average number of characters in a token also depends on the model (most models have subword tokens of variable length). Make sure to pay attention to the specified context length of the sentence transformer you are using. Many models, however, are more computationally efficient with shorter inputs, so you may need to experiment to find the best chunk size for your use case.
# Number of *characters*, not *tokens*, in a chunk
CHUNK_SIZE = 2048
# Number of *characters*, not *tokens*, to overlap between chunks
CHUNK_OVERLAP = 128
Load and Split Documents¶
LangChain provides many convenient utilities for loading different kind of files in a way that's compatible with other Langchain functions, such as uploading files to a vector database. Because each file format is different, each file format usually requires some sort of special handling to load correctly. Despite this, LangChain provides a (mostly) consistent interface for loading files, so adding support for new files is usually straightforward.
For brevity, in this tutorial we will only support loading .csv, .pdf, and .txt files. All others will be handled as if they are .txt files. To do this, we will demonstrate the use of the CSVLoader, PyPDFLoader, and TextLoader classes.
For more details on supported document loaders, see the official LangChain documentation.
We will use LangChain's split_documents function to split the documents into smaller chunks before creating the embeddings.
def split_documents(
file_path: str,
) -> list[langchain.docstore.document.Document]:
"""Split a document into smaller pieces for processing.
LangChain has many different types of document loaders. For brevity, we will
only use the CSVLoader, the PyPDFLoader, and the TextLoader.
Args:
file_path: Path to the uploaded file (specified by gradio).
Returns:
A list of documents, each containing a chunk of the original document.
Raises:
ValueError: If the file is not specified.
"""
file = pathlib.Path(file_path)
if not file or not file.exists():
raise ValueError("File is required")
# Switch over file types to determine how to load the document
if file.suffix == ".csv":
loader = langchain.document_loaders.CSVLoader(file)
# There is no need to split the document if it is a CSV file, each
# row will be treated as a separate document automatically.
documents = loader.load()
elif file.suffix == ".pdf":
loader = langchain.document_loaders.PyPDFLoader(str(file))
pages = loader.load()
text_splitter = langchain.text_splitter.RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP
)
documents = text_splitter.split_documents(pages)
else:
loader = langchain.document_loaders.TextLoader(file)
pages = loader.load()
text_splitter = langchain.text_splitter.RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP
)
documents = text_splitter.split_documents(pages)
return documents
Create the Qdrant collection¶
Before we can embed our documents and upload them to the vector database, we have to first instantiate the Qdrant collection (similar to a table in a relational database).
LangChain and the Qdrant python client make this easy. In the function below, we connect to a Qdrant vector database (the one we started earlier) and create a new collection if it does not exist. LangChain will then use the created client wrapper (langchain_qdrant.QdrantClient) for retrieval below.
We will use the Cosine Similarity to find the most similar documents to a given query. The exact specifics of how sentence embeddings and similarity search work are beyond the scope of this tutorial, but you can find more information online, such as Qdrant's vector search explainer.
def load_qdrant_vectordb(
qdrant_host: str,
collection_name: str,
embedding_function: langchain_huggingface.HuggingFaceEmbeddings,
) -> langchain_qdrant.QdrantVectorStore:
"""Load a Qdrant vector database, creating a new collection if it does not exist.
Args:
qdrant_host: Hostname of the Qdrant server.
collection_name: Name of the collection to use.
embedding_function: HuggingFaceEmbeddings object to use for embedding text.
Returns:
A LangChain Qdrant object for interacting with the vector database
"""
# The embedding size could be hard coded, but it's easier to get it from the model
embedding_size = (
embedding_function.client.get_sentence_embedding_dimension()
or embedding_function.client.encode(["test"]).shape[1]
)
qdrant = qdrant_client.QdrantClient(qdrant_host)
if collection_name not in [
collection.name for collection in qdrant.get_collections().collections
]:
qdrant.create_collection(
collection_name,
vectors_config=qdrant_client.models.VectorParams(
size=embedding_size,
distance=qdrant_client.models.Distance.COSINE,
),
)
return langchain_qdrant.QdrantVectorStore(
qdrant, collection_name, embedding_function
)
Create Sentence Embeddings for Document Chunks¶
LangChain provides convenient wrappers around Hugging Face Sentence Transformer models (langchain_huggingface.HuggingFaceEmbeddings) and Qdrant (langchain_qdrant.QdrantClient) to make it easy to create sentence embeddings and add them to a Qdrant collection.
Because LangChain makes this step so easy, we don't need a separate function! This is handled automatically when we pass in documents to the langchain_qdrant.QdrantClient.add_documents method.
Add the documents to the Qdrant database¶
Finally, we have a function that takes in a file_path (pointing at a document), splits it (using our function above), loads the vector database, and adds the embeddings to the Qdrant collection (creating the embeddings is handled implicitly by the QdrantClient).
def upload_and_create_vector_store(
file_paths: list[str],
embedding_model_id: str,
collection_name: str,
qdrant_host: str,
model_kwargs: dict[str, Any] | None = None,
encode_kwargs: dict[str, Any] | None = None,
) -> str:
"""Upload files to qdrant, creating a vector store for the session, if needed.
Args:
file_paths: Path to the uploaded file (specified by gradio).
embedding_model_id: The Hugging Face model ID to use for embedding the documents.
collection_name: The name of the collection to create in qdrant.
qdrant_host: The host of the qdrant server.
model_kwargs: Additional arguments to pass to the Hugging Face model.
encode_kwargs: Additional arguments to pass to the Hugging Face encode method.
Returns:
A message indicating that the vector store has been, to be displayed in the Gradio interface.
"""
for file_path in file_paths:
documents = split_documents(file_path)
embedding_function = langchain_huggingface.HuggingFaceEmbeddings(
model_name=embedding_model_id,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
vectordb = load_qdrant_vectordb(
qdrant_host, collection_name, embedding_function
)
vectordb.add_documents(documents)
return "Vector store created."
Create LangChain chain for retrieving documents and prompting the LLM¶
Now that we have our documents loaded into the vector database, we can create a LangChain chain that retrieves the most similar documents to a given query and prompts the LLM with the retrieved documents.
The LangChain chain will have the following steps:
- Load the embedding model, Qdrant VectorDB client, and OpenAI client.
- Ask the LLM to create a query for the VectorDB based on the user's input and chat history
- Retrieve the most similar documents to the query from the VectorDB
- Create a new prompt for the LLM that includes the retrieved documents
- Ask the LLM to generate a response based on the new prompt (with documents), the user's instructions, and the chat history
Architecture Overview¶
The diagram below illustrates the flow of data between the various LangChain components we will construct and use for the conversational RAG chain.

# We need a place to store the chat message histories and the chains for each user session.
# Keys are session IDs, values are the chat message histories and chains for that session.
CHAT_HISTORY_STORE: dict[
str, langchain_community.chat_message_histories.ChatMessageHistory
] = {}
CHAINS_STORE: dict[
str, langchain_core.runnables.history.RunnableWithMessageHistory
] = {}
def load_chain(
session_id: str,
system_prompt: str,
qdrant_host: str,
collection_name: str,
embedding_model_id: str,
openai_url: str | None,
openai_model: str,
embedding_model_kwargs: dict[str, Any] | None = None,
embedding_model_encode_kwargs: dict[str, Any] | None = None,
) -> langchain_core.runnables.history.RunnableWithMessageHistory:
"""Create a chain for retrieving answers to questions from a document store and prompting the LLM.
Args:
session_id: The session ID to use for storing the history of the conversation.
system_prompt: The system prompt to pass to the LLM.
qdrant_host: The host of the qdrant server.
collection_name: The name of the collection to use in qdrant.
embedding_model_id: The HuggingFace model ID to use for embedding the documents.
openai_url: The URL of the OpenAI API.
openai_model: The OpenAI model to use for answering questions.
embedding_model_kwargs: Additional arguments to pass to the HuggingFace model.
embedding_model_encode_kwargs: Additional arguments to pass to the HuggingFace encode method.
Returns:
A chain that can be used to retrieve answers to questions from a document store and prompt the LLM.
"""
# Load the embedding model, the OpenAI model, and the Qdrant vector database
embedding_function = langchain_huggingface.HuggingFaceEmbeddings(
model_name=embedding_model_id,
model_kwargs=embedding_model_kwargs,
encode_kwargs=embedding_model_encode_kwargs,
)
call_llm = langchain_openai.ChatOpenAI(
base_url=openai_url, model=openai_model
)
vectordb = load_qdrant_vectordb(
qdrant_host, collection_name, embedding_function
)
retriever = vectordb.as_retriever(search_kwargs={"k": 3})
# Ask the LLM to reformulate user prompts as queries for the document store
# Often the chat history will contain context that is not relevant to the question
# and/or will not fit within the maximum context length of the language model
# The LLM can help us identify the relevant parts of the chat history and formulate
# a (relatively brief) query that is more likely to retrieve the correct documents
# See the docs for more information:
# https://langchain.readthedocs.io/en/latest/chains.html#langchain.chains.create_history_aware_retriever
contextualize_question_system_prompt = (
"Given a chat history and the latest user question "
"which might reference context in the chat history, formulate a standalone question "
"which can be understood without the chat history. If the question is not related to the chat history, "
"leave the question intact. Do NOT answer the question, "
"just reformulate it if needed and otherwise return it as is."
)
contextualize_question_prompt = (
langchain.prompts.ChatPromptTemplate.from_messages(
[
("system", contextualize_question_system_prompt),
langchain.prompts.MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
)
# Retrieve the most relevant documents for a given question from the vector database
history_aware_retriever = langchain.chains.create_history_aware_retriever(
call_llm, retriever, contextualize_question_prompt
)
# Create a new prompt including the chat history and the retrieved documents
document_prompt = langchain.prompts.PromptTemplate(
input_variables=["page_content", "source"],
template="Context:\n{page_content}\n\nSource: {source}",
)
user_chat_prompt = langchain.prompts.ChatPromptTemplate.from_messages(
[
("system", system_prompt),
langchain.prompts.MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
# Query the LLM with the chat history and the most relevant documents
user_chat_chain_with_documents = (
langchain.chains.combine_documents.create_stuff_documents_chain(
call_llm, user_chat_prompt, document_prompt=document_prompt
)
)
# Compose the retrieval and chat chains
rag_chain = langchain.chains.create_retrieval_chain(
history_aware_retriever, user_chat_chain_with_documents
)
# Create a chain that stores the chat message history for the session, using the RAG chain
conversation_rag_chain = (
langchain_core.runnables.history.RunnableWithMessageHistory(
rag_chain,
get_session_history=lambda: CHAT_HISTORY_STORE.get(
session_id,
langchain_community.chat_message_histories.ChatMessageHistory(),
),
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
)
return conversation_rag_chain
Manually invoking the LangChain chains¶
Now that we have factories for our chains, we can manually invoke them, to show how they can be embedded in a larger application.
Note
You will need to have the OPENAI_API_KEY environment variable set to your OpenAI API key in order to run the code below.
# # You can set the OPENAI_API_KEY environment variable using the lines below.
# import os
# os.environ["OPENAI_API_KEY"] = "sk-1234567890abcdef"
test_session_id = "test-session-id"
test_chain = load_chain(
session_id=test_session_id,
system_prompt="You are a helpful assistant who strives to provide accurate and helpful answers to user questions. Please help the user given the following chat. {context}",
qdrant_host=QDRANT_HOST,
collection_name=test_session_id,
embedding_model_id=EMBEDDING_MODEL_ID,
openai_url=None, # Use the default OpenAI API URL, note this requires setting the OPENAI_API_KEY environment variable
openai_model="gpt-4o-mini",
embedding_model_kwargs=MODEL_KWARGS,
embedding_model_encode_kwargs=QUERY_ENCODE_KWARGS,
)
test_chain.invoke(
{"input": "What is the capital of France?"},
config={"configurable": {"session_id": test_session_id}},
)
/Users/jennifercwagenberg/.cache/huggingface/modules/transformers_modules/nomic-ai/nomic-bert-2048/c1b1fd7a715b8eb2e232d34593154ac782c98ac9/modeling_hf_nomic_bert.py:98: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature. state_dict = loader(resolved_archive_file) <All keys matched successfully> <All keys matched successfully>
Disabled 37 dropout modules from model type <class 'transformers_modules.jxm.cde-small-v1.6ab272bad48e585bcb5c6ff1e033eebe68248315.model.BiEncoder'> modified 12 rotary modules – set rotary_start_pos to 512 Disabled 74 dropout modules from model type <class 'transformers_modules.jxm.cde-small-v1.6ab272bad48e585bcb5c6ff1e033eebe68248315.model.DatasetTransformer'>
{'input': 'What is the capital of France?',
'chat_history': [],
'context': [],
'answer': 'The capital of France is Paris.'}
Create a Gradio interface¶
Finally, now that we have a LangChain chain that can retrieve documents and prompt the LLM, it's time to use it in an application. We will use Gradio to create a simple web interface that allows users to upload documents and chat with an LLM about those documents.
The create_vector_store_button, when clicked, will create the vector store from the uploaded documents. The ChatInterface will use the chat_bot function to invoke the LangChain chain defined above.
The user can also optionally modify the system prompt to change the behavior of the LLM.
import uuid
import gradio as gr
import requests
MOST_RECENT_PROMPT: str | None = None
def fetch_session_hash(request: gr.Request) -> str | None:
"""Fetch the session hash from the request.
We will use the session hash as the Qdrant collection name so that each
individual session has its own collection in Qdrant.
Args:
request: The Gradio request object.
Returns:
The session hash.
"""
return request.session_hash
def chat_bot(
message: str,
history: list[list[str]],
session: str,
system_prompt: str,
openai_url: str | None,
openai_model: str,
embedding_model_id: str,
qdrant_url: str,
) -> str:
"""Chat with the RAG conversation agent.
Args:
message: The message from the user.
history: The chat history. Unused, because langchain handles its own copy of the chat history.
session: The session hash.
system_prompt: The system prompt.
openai_url: The URL of the OpenAI API.
openai_model: The OpenAI model to use for answering questions.
embedding_model_id: The HuggingFace model ID to use for embedding the documents.
qdrant_url: The URL of the qdrant server.
Returns:
The response from the RAG conversation agent.
"""
global MOST_RECENT_PROMPT
MOST_RECENT_PROMPT = message
if session not in CHAINS_STORE:
CHAINS_STORE[session] = load_chain(
session,
system_prompt,
qdrant_url,
session,
embedding_model_id,
openai_url,
openai_model,
embedding_model_kwargs=MODEL_KWARGS,
embedding_model_encode_kwargs=QUERY_ENCODE_KWARGS,
)
chain = CHAINS_STORE[session]
response = chain.invoke(
{"input": message}, config={"configurable": {"session_id": session}}
)
return response["answer"]
def see_stainedglass_reconstruction(openai_url: str) -> str:
"""Reconstruct the most recent prompt using the StainedGlass API.
Args:
openai_url: The URL of the OpenAI API.
Returns:
The reconstructed prompt.
"""
if MOST_RECENT_PROMPT is None:
return "No prompt to reconstruct"
request = {
"messages": [
{"role": "user", "content": MOST_RECENT_PROMPT},
],
"return_transformed_embeddings": False,
"return_reconstructed_prompt": True,
"return_plain_text_embeddings": False,
}
response = requests.post(f"{openai_url}/stainedglass", json=request).json()
return response["reconstructed_prompt"]
def setup_chatbot_web_app(
qdrant_host: str,
openai_url: str | None,
openai_model: str,
show_reconstructed_prompt: bool = False,
) -> gr.Blocks:
"""Set up the Gradio interface for the RAG conversation agent.
Args:
qdrant_host: The host of the qdrant server.
openai_url: The URL of the OpenAI API.
openai_model: The OpenAI model to use for answering questions.
show_reconstructed_prompt: Whether to show the reconstructed prompt.
Returns:
The Gradio interface for the RAG conversation agent.
"""
with gr.Blocks() as demo, gr.Row():
with gr.Column(scale=1, variant="panel"):
gr.Markdown("## RAG Conversation Agent")
system_prompt = gr.Textbox(
label="System instruction",
lines=3,
value="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Keep the answer concise. {context}",
)
session = gr.Textbox(value=uuid.uuid1, label="Session")
chat_interface = gr.ChatInterface(
fn=lambda message, history, session, system_prompt: chat_bot(
message,
history,
session,
system_prompt,
openai_url,
openai_model,
EMBEDDING_MODEL_ID,
qdrant_host,
),
additional_inputs=[
session,
system_prompt,
],
)
demo.load(fetch_session_hash, None, session)
if show_reconstructed_prompt:
gr.Markdown(
"### Attempted Text Reconstruction of Most Recent Prompt Protected by Stained Glass Transform"
)
most_recent_prompt = gr.Textbox(
MOST_RECENT_PROMPT,
lines=3,
placeholder="Attempted text reconstruction...",
label="",
)
assert openai_url is not None
chat_interface.textbox.submit(
lambda: see_stainedglass_reconstruction(openai_url),
None,
most_recent_prompt,
trigger_mode="always_last",
)
chat_interface.submit_btn.click(
lambda: see_stainedglass_reconstruction(openai_url),
None,
most_recent_prompt,
trigger_mode="always_last",
)
with gr.Column(scale=1, variant="panel"):
gr.Markdown("## Upload Document")
file = gr.File(type="filepath", file_count="multiple")
with gr.Row(equal_height=True), gr.Column(variant="compact"):
create_vector_store_button = gr.Button(
"Create vector store", variant="primary", scale=1
)
vector_index_msg_out = gr.Textbox(
show_label=False,
lines=1,
scale=1,
placeholder="Please create vector store...",
)
create_vector_store_button.click(
lambda arg1, arg2: upload_and_create_vector_store(
arg1,
EMBEDDING_MODEL_ID,
arg2,
qdrant_host,
model_kwargs=MODEL_KWARGS,
encode_kwargs=DOCUMENT_ENCODE_KWARGS,
),
[file, session],
vector_index_msg_out,
)
return demo
Create RAG Chatbot with OpenAI¶
We can now test this RAG chatbot using the OpenAI API. The Vector Database is running in the Qdrant docker container locally, but all LLM queries will be sent to the OpenAI API.
Tip
You must provide your own OpenAI API key to use their official API and models. It can be specified using the OPENAI_API_KEY environment variable.
OPENAI_URL = None
OPENAI_MODEL = "gpt-4o-mini"
# # You can set the OPENAI_API_KEY environment variable using the lines below.
# import os
# os.environ["OPENAI_API_KEY"] = "sk-1234567890abcdef"
Example
Try out the demo with some sample documents. After uploading the files and clicking the "Create Vector Store" button, your chatbot will now be able to retrieve information from those documents. You can upload your own documents, or you can download a few sample financial documents below.
demo = setup_chatbot_web_app(
qdrant_host=QDRANT_HOST,
openai_url=OPENAI_URL,
openai_model=OPENAI_MODEL,
)
demo.launch(inline=False)
Running on local URL: http://127.0.0.1:7866 To create a public link, set `share=True` in `launch()`.
Create Private RAG Chatbot with Stained Glass Transform Proxy¶
The OpenAI API will see all the queries and responses in plaintext (including any documents retrieved from the vector database), so it is not private and not suitable for sensitive information. To make the chatbot private, we will use the Stained Glass Transform Proxy running locally to transform the queries into protected input embeddings before sending them to another LLM model provider. The LLM model provider will not be able to see the original queries, only the protected input embeddings.
Deploy Stained Glass Transform Proxy¶
Stained Glass Transform Proxy is an OpenAI-compatible REST API that can be used to replace references to the OpenAI API in your application. It communicates with an LLM Model Provider using transformed embeddings from Stained Glass Transform.
This proxy runs within the enterprise alongside the data. The plaintext input is transformed before leaving the proxy, so the model provider never sees the original input.
STAINED_GLASS_TRANSFORM_PROXY_PORT = 8600
STAINED_GLASS_TRANSFORM_PROXY_URL = (
f"http://localhost:{STAINED_GLASS_TRANSFORM_PROXY_PORT}/v1"
)
STAINED_GLASS_TRANSFORM_MODEL = "mistral-7b-instruct"
STAINED_GLASS_TRANSFORM_PROXY_DOCKER_IMAGE = (
"stainedglass-proxy:0.12.4-57059a3-stac-workshop"
)
STAINED_GLASS_LLM_API_URL = "http://llm-api-stac.stage-01.stage.protopia.ai"
# Launch qdrant docker container
sgt_proxy_container_id = subprocess.run(
f"docker run -d -p {STAINED_GLASS_TRANSFORM_PROXY_PORT}:{STAINED_GLASS_TRANSFORM_PROXY_PORT} -e SGP_INFERENCE_SERVICE_HOST={STAINED_GLASS_LLM_API_URL} -e SGP_SGT_PATH=/app/sgt_model.pt -e SGP_PROMPT_SCHEMA_TYPE=chat {STAINED_GLASS_TRANSFORM_PROXY_DOCKER_IMAGE}",
shell=True,
encoding="utf-8",
capture_output=True,
).stdout.strip()
print(f"""Container {qdrant_container_id} started.
Run docker logs -f {qdrant_container_id} to see logs.""")
Container c3a3ec74342c29a4eb87292b30057b395dfb48808a0b84b26e04206199721ea9 started. Run docker logs -f c3a3ec74342c29a4eb87292b30057b395dfb48808a0b84b26e04206199721ea9 to see logs.
Launch Gradio app connected to Stained Glass Transform Proxy¶
We will now launch a Gradio app that connects to the Stained Glass Transform Proxy. The app will allow users to do a RAG chat using protected inputs to the LLM model provider.
Observing transformed inputs and their reconstructions¶
Although the Stained Glass Transform Proxy is OpenAI-API-compatible, it also provides an additional v1/stainedglass endpoint to see the transformed input and an attempted reconstruction. Note that we will specify the show_reconstructed_prompt parameter to True to add a textbox to the Gradio interface to show the reconstructed prompt after each time the user sends a message. It only shows an attempted reconstruction of the protected input of the last message sent by the user, for simplicity in this demo. This is not what is sent to the LLM model provider (they see protected input embeddings), but rather is an attempt to reconstruct text from those embeddings.
protected_demo = setup_chatbot_web_app(
qdrant_host=QDRANT_HOST,
openai_url=STAINED_GLASS_TRANSFORM_PROXY_URL,
openai_model=STAINED_GLASS_TRANSFORM_MODEL,
show_reconstructed_prompt=True,
)
protected_demo.launch(inline=False)
Running on local URL: http://127.0.0.1:7867 To create a public link, set `share=True` in `launch()`.
Cleanup created resources¶
This will close the docker containers that you started as well as close the gradio applications that were created above.
demo.close()
protected_demo.close()
!docker stop {qdrant_container_id}
!docker stop {sgt_proxy_container_id}
Closing server running on port: 7866 Closing server running on port: 7867 c3a3ec74342c29a4eb87292b30057b395dfb48808a0b84b26e04206199721ea9 e227bf3cdbd841b7b62ad064256b313dda29b5306e83c8195b5581fadf25f2c1